
Megatron-LM
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
- Mohammad Shoeybi et al. 2019.
- NVIDIA Corp.
Summary
-
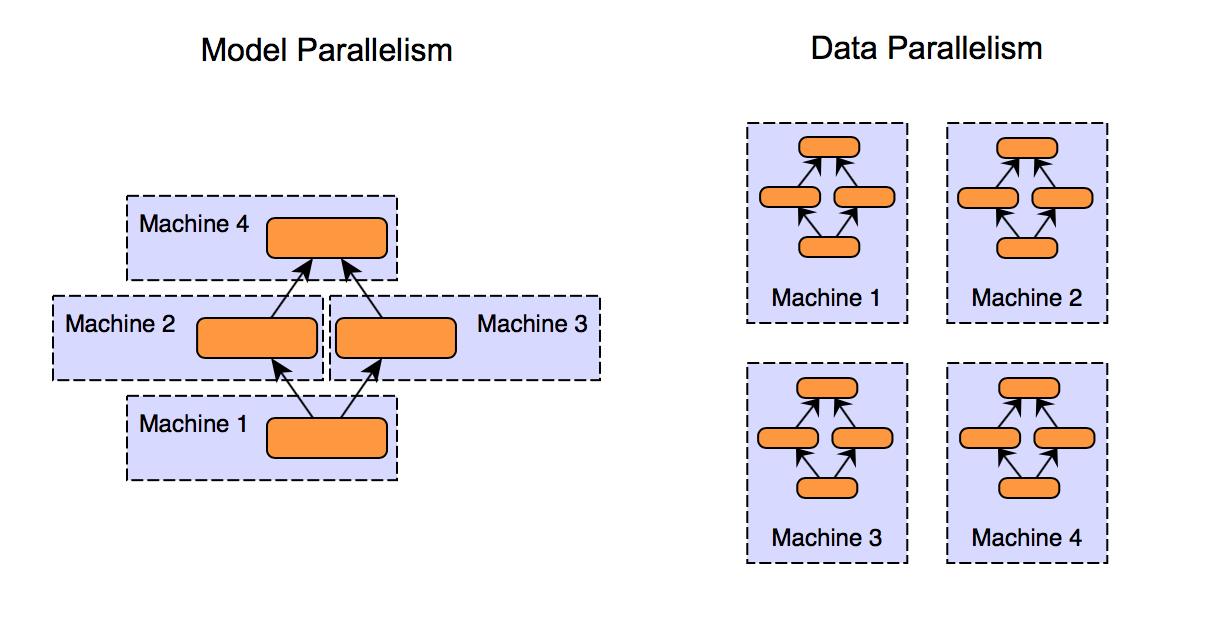
Transformer Language Model Parallelism
-
새로운 컴파일러나 기존 라이브러리 변경 없이 Very Big-Model을 학습시킬 수 있는 Megatron-LM을 제안 (PyTorch 기반)
-
8.3 billion 파라미터를 성공적으로 학습시킴 (GPT-3: 175 billion)
Backgrounds

-
최근 Large-scale의 Transformer를 이용한 Language Model(LM)이 대세
-
하지만 너무 큰 모델은 하드웨어적 메모리 제약으로 인해 학습이 어려움
-
이를 해결하기 위해 여러 방법이 나왔지만, 새로운 컴파일러 혹은 기존 라이브러리를 건드려야 한다는 불편함이 있음
-
새로운 컴파일러나 기존 라이브러리를 변경하는 일 없이 간단한 방법으로 Model Parallelism 하는 Simple하면서도 Efficient한 방법 제안
Model Parallel Transformers
- Transformer는 self attention block과 multi-layer perceptron (MLP) 로 구성되어 있음.
MLP Block

MLP Block Model Parallelism

위의 공식을 따르는 MLP 블록을 Model Parallel하게 적용하기 위해서는 2가지 방법이 있을 수 있음.
방법 1: 입력 X를 column으로, weight matrix A를 row로 split하는 방법.

하지만 이 방법은 GeLU(X1A1 + X2A2) 6= GeLU(X1A1) + GeLU(X2A2)이 성립하지 않기 때문에 GeLU 입력 전에 동기화가 필요하다는 단점이 있음.
방법 2: weight matrix A를 column으로 split하는 방법이 있음.

이 방법은 위의 그림에서 볼 수 있듯이, GeLU 입력 전후로도 GPU간에 통신이 필요 없다는 장점이 있음.
정리

- Code
import torch
import torch.nn as nn
class Method1(nn.Module):
def __init__(self):
super().__init__()
self.a1 = nn.Linear(5, 10, bias=False)
self.a2 = nn.Linear(5, 10, bias=False)
def forward(self, x):
x1, x2 = torch.chunk(x, 2, dim=-1)
y1 = self.a1(x1)
y2 = self.a2(x2)
y = y1 + y2
return y
class Method2(nn.Module):
def __init__(self):
super().__init__()
self.a1 = nn.Linear(10, 5, bias=False)
self.a2 = nn.Linear(10, 5, bias=False)
def forward(self, x):
y1 = self.a1(x)
y2 = self.a2(x)
y = torch.cat((y1, y2), dim=-1)
return y
gelu = nn.GELU()
a = torch.FloatTensor([[i for i in range(10)]])
b = torch.FloatTensor([[i for i in range(1, 11)]])
- 방법1 Test
print("GeLU(X1A1) + GeLU(X2A2) != GeLU(X1A1 + X2A2)\n")
print(gelu(a + b), end="\n\n")
print(gelu(a) + gelu(b))
GeLU(X1A1) + GeLU(X2A2) != GeLU(X1A1 + X2A2)
tensor([[ 0.8413, 2.9960, 5.0000, 7.0000, 9.0000, 11.0000, 13.0000, 15.0000,
17.0000, 19.0000]])
tensor([[ 0.8413, 2.7958, 4.9504, 6.9958, 8.9999, 11.0000, 13.0000, 15.0000,
17.0000, 19.0000]])
- 방법2 Test
print("GeLU(concat(X1A1, X2A2)) == concat(GeLU(X1A1) + GeLU(X2A2))\n")
print(gelu(torch.cat((a, b))), end="\n\n")
print(torch.cat((gelu(a), gelu(b))))
GeLU(concat(X1A1, X2A2)) == concat(GeLU(X1A1) + GeLU(X2A2))
tensor([[ 0.0000, 0.8413, 1.9545, 2.9960, 3.9999, 5.0000, 6.0000, 7.0000,
8.0000, 9.0000],
[ 0.8413, 1.9545, 2.9960, 3.9999, 5.0000, 6.0000, 7.0000, 8.0000,
9.0000, 10.0000]])
tensor([[ 0.0000, 0.8413, 1.9545, 2.9960, 3.9999, 5.0000, 6.0000, 7.0000,
8.0000, 9.0000],
[ 0.8413, 1.9545, 2.9960, 3.9999, 5.0000, 6.0000, 7.0000, 8.0000,
9.0000, 10.0000]])
위의 코드에서 방법2로 계산시, Model Parallel하게 MLP Block을 진행할 수 있음을 알 수 있음.
Attention Block

- MLP Block과 같은 방법으로 Model Parallelism을 적용할 수 있음.
Model Parallelism

-
결과적으로 트랜스포머 블록 하나당 총 4번의 GPU간 통신만 있으면 되는 구조가 됨.
-
ALL-Reduce란 해당 블록의 결과물을 모든 프로세서가 Return하는 것을 의미함.
Experiment

Leave a comment